Retrieval-Augmented Generation for LLMs: How and Why It Matters
This comprehensive guide explores how RAG is transforming the capabilities of language models, its implementation, limitations, and whether it truly solves the fundamental problems faced by modern AI systems.
I've been building with LLMs for the better part of two years now. And if there's one thing I've learned the hard way, it's this: a language model without access to real, grounded information is a very eloquent liar.
That's not me being dramatic. Ask GPT-4 about something that happened after its training cutoff, and it'll confidently make something up. Ask Claude about your company's internal documentation, and it'll hallucinate a plausible-sounding answer that has nothing to do with reality. These models are extraordinary at language—and genuinely dangerous when it comes to facts.
This is where Retrieval-Augmented Generation comes in. And while it's not a magic fix (nothing in AI is), it's the single most practical thing we have right now for making LLMs actually useful in production.
RAG in Plain English
Here's the concept, stripped of the jargon: instead of asking an LLM to answer from memory, you first go fetch the relevant information from a knowledge base, hand it to the model, and say "answer based on this."
That's it. That's the core idea.
The technical implementation has four steps, and they happen in sequence every time a user submits a query:
Step 1 — Figure out what the user is really asking. The system takes the raw query and processes it. Sometimes that means rephrasing it, sometimes it means breaking it into sub-questions. The goal is to turn a messy human question into something that can drive an effective search.
Step 2 — Go find the relevant stuff. This is the retrieval part. The system searches through whatever knowledge base you've connected—could be your documentation, a database, a collection of PDFs, an API. It pulls back the chunks of information that seem most relevant to the query.
Step 3 — Package it up. The retrieved information gets combined with the original question into a prompt. Think of it as handing the LLM a cheat sheet along with the exam question.
Step 4 — Generate the answer. Now the LLM does what it does best—produce fluent, coherent text—but grounded in the actual information you retrieved, not just whatever patterns it learned during training.
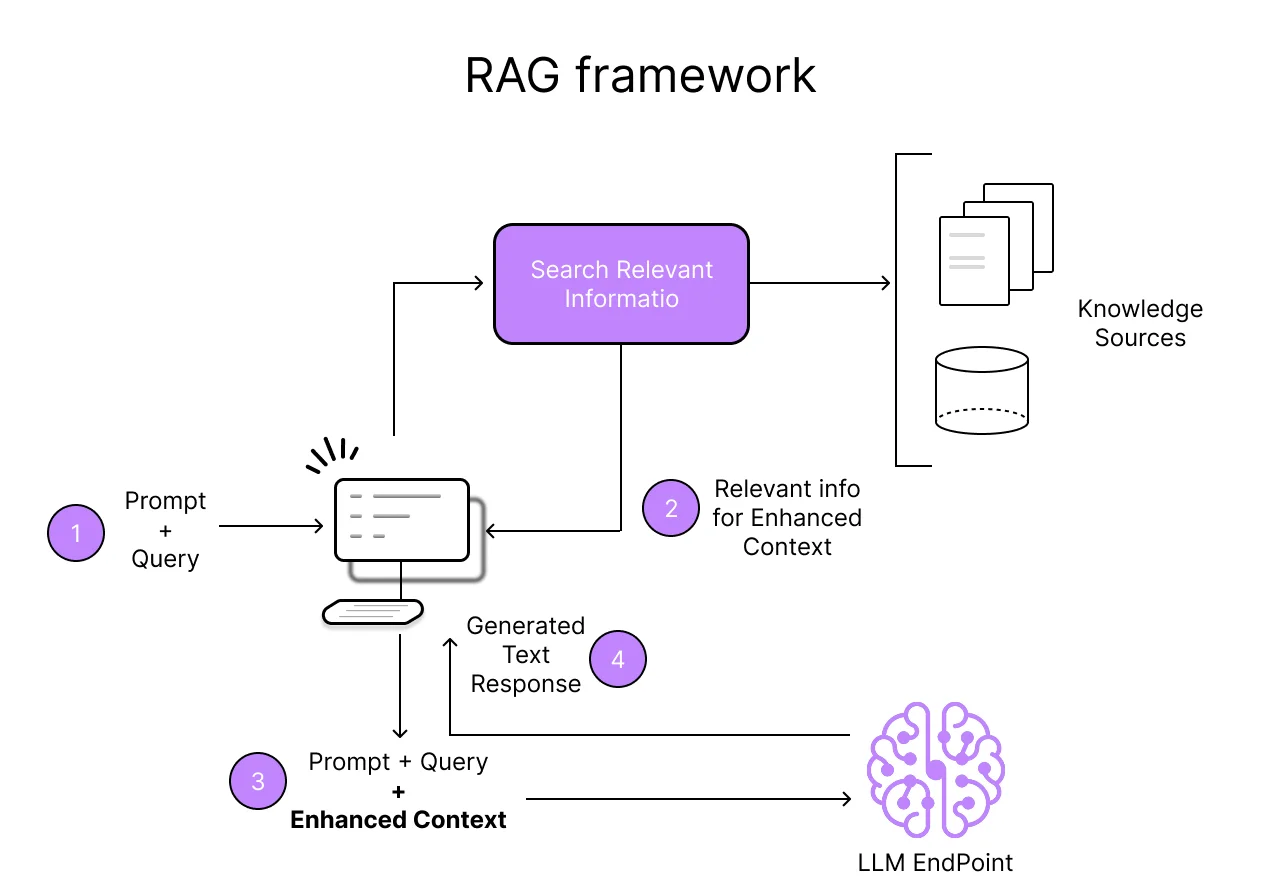
The beauty of this approach is that it lets you keep the thing LLMs are genuinely good at (language, reasoning, synthesis) while patching the thing they're genuinely bad at (knowing facts, staying current, accessing your data).
Why We Needed This in the First Place
If you've worked with LLMs in any production context, you already know the pain points. But let me spell them out, because understanding the problems is what makes RAG's value click.
The Hallucination Problem Is Worse Than People Realize
Everyone talks about hallucinations, but until you've deployed an LLM and watched it confidently cite a paper that doesn't exist, or tell a customer your product has a feature it doesn't have, you don't fully appreciate how bad this is.
The issue is fundamental to how these models work. They're not looking up facts—they're predicting the most statistically likely next token based on patterns in training data. Sometimes that produces truth. Sometimes it produces very convincing fiction. And the model has no way to tell you which one you're getting.
In healthcare, finance, legal—anywhere that facts matter—this is a dealbreaker. You can't deploy a system that occasionally makes things up with absolute confidence.
The Knowledge Cutoff Is a Real Problem
GPT-4's training data has a cutoff around April 2023. Claude's is roughly October 2024. That means anything that's happened since then—new products, updated regulations, recent events—simply doesn't exist in the model's world.
For a chatbot answering general knowledge questions, this might be annoying but manageable. For a business tool that needs to reference current pricing, recent company announcements, or the latest version of a spec? It's unusable.
Your Data Doesn't Exist to the Model
This is the one that bit us personally. We tried using an LLM to answer questions about our own product documentation, and of course it had no idea. Our docs weren't in its training data. Why would they be?
Fine-tuning is the traditional answer here—train the model on your data. But fine-tuning is expensive, slow, hard to update, and raises legitimate security concerns about data leaking into model weights. For most organizations, it's impractical as a primary approach.
What RAG Actually Gets You
Alright, so what happens when you wire up retrieval properly? From our experience and from what we've seen across the industry:
Accuracy improves meaningfully. The numbers I've seen reported range from 15% to 35% improvement in factual accuracy on benchmark tasks. In our own testing with product documentation Q&A, the difference was even more stark—we went from answers that were "plausible but wrong" about half the time to answers that were verifiably correct in the high 80s percentile.
Your information stays current. Since the model is pulling from your knowledge base at query time, updating the information is as simple as updating the source documents. No retraining, no fine-tuning, no waiting weeks for a new model version. We push doc updates and they're reflected in answers within minutes.
You can actually cite your sources. This is underrated. When a RAG system generates an answer, it can point to exactly which documents it drew from. That audit trail changes the conversation with compliance teams, legal departments, and anyone else who needs to verify that the AI isn't just making things up.
It's cheaper than the alternatives. Fine-tuning a large model on proprietary data can cost thousands of dollars and take days. Setting up a RAG pipeline costs a fraction of that, and updating it is essentially free. For teams that don't have unlimited AI budgets (which is most teams), this matters a lot.
Building a RAG System: What You're Actually Signing Up For
If you're considering implementing RAG, here's what the real work looks like. It's more involved than the concept suggests, but it's also more tractable than fine-tuning.
Your Knowledge Base Is Everything
Garbage in, garbage out applies to RAG more than almost anything else in AI. If your knowledge base is messy, outdated, or poorly organized, your RAG system will produce messy, outdated, or poorly organized answers.
We've connected RAG systems to all sorts of sources—PDF documentation, Notion wikis, Confluence spaces, code repositories, API docs, even spreadsheets. The source format matters less than the content quality. Clear, well-written, well-organized source material produces dramatically better answers than a pile of unstructured documents.
Chunking Is Where the Art Lives
This is the part that surprised me most when I first built a RAG pipeline. You can't just feed entire documents into a vector database. You have to break them into chunks—but how you chunk makes a huge difference.
Too small, and you lose context. The retrieved chunk might contain the answer but not enough surrounding information for the LLM to make sense of it. Too large, and you waste precious context window space on irrelevant text, or worse, you dilute the relevant signal with noise.
We've settled on a sliding-window approach with about 500-token chunks and 100-token overlaps for most of our documentation. But honestly, the "right" chunking strategy varies by content type. Legal documents need different treatment than API docs, which need different treatment than conversational FAQ content.
Don't underestimate the importance of this step. We've seen cases where improving chunking alone improved answer quality by 20-30%, without changing anything else in the pipeline.
Picking a Vector Database
You need somewhere to store your embedded chunks and search them efficiently. The market has gotten crowded here, which is both good (more options) and confusing (which one?).
Here's our honest take on the major players:
- Pinecone — managed, easy to get started, solid filtering capabilities. Good if you don't want to manage infrastructure and your dataset isn't enormous.
- Weaviate — open-source, surprisingly feature-rich, handles hybrid search well out of the box. Our go-to recommendation for teams that want control without building everything from scratch.
- Chroma — lightweight, developer-friendly, great for prototyping and smaller-scale projects. Not where we'd point you for production workloads at scale.
- Qdrant — impressive performance characteristics, good filtering, Rust-based so it's fast. Growing quickly in the enterprise space.
- Milvus — built for scale. If you're dealing with billions of vectors, this is where you look. Overkill for most startups and mid-market use cases.

Making Retrieval Actually Work
Basic RAG—embed the query, find the nearest vectors, return the top-k results—works surprisingly well for simple use cases. But it breaks down quickly on complex queries.
Here's what we've found helps:
Hybrid search (combining vector similarity with keyword matching) catches things that pure semantic search misses. Someone searching for "error code 4032" needs exact keyword matching, not just semantic similarity.
Query decomposition makes a real difference for multi-part questions. "Compare the pricing and features of Pinecone versus Weaviate for a 10M vector dataset" is really three questions in one. Breaking it apart and retrieving for each sub-question separately, then combining the results, produces much better answers.
Re-ranking retrieved results before passing them to the LLM helps filter out noise. We use a cross-encoder re-ranker that scores each retrieved chunk against the original query, keeping only the truly relevant ones. This adds latency but meaningfully improves answer quality.
The Hard Parts Nobody Warns You About
Building a proof-of-concept RAG system takes a weekend. Building a production RAG system that actually works well? That takes months of iteration. Here are the things that tripped us up:
Retrieval latency adds up. Every hop in the pipeline adds milliseconds. Embedding the query, searching the vector database, re-ranking results, then running the LLM generation—by the time you're done, you can easily be looking at 3-5 second response times. For interactive applications, that's rough. We've invested heavily in caching frequently asked queries and pre-computing embeddings for common question patterns.
Keeping the knowledge base current is an ongoing job. It sounds simple—just update the docs and re-embed. In practice, you need automated pipelines to detect when source documents change, re-chunk the updated content, generate new embeddings, and swap them into the database without downtime. We built a webhook-based system that triggers re-indexing whenever our documentation repo gets updated. It works, but it was non-trivial to get right.
RAG doesn't fix bad reasoning. This was a humbling realization. Even with perfect retrieval—even when the system finds exactly the right document chunk—the LLM can still misinterpret the information, draw wrong conclusions, or fail to connect dots that seem obvious to a human reader. RAG improves factual accuracy. It doesn't make the model smarter.
The "I don't know" problem is real. When a RAG system can't find relevant information, you want it to say "I don't know." What actually happens, more often than you'd like, is that the LLM fills in the gaps with hallucinated information, ignoring the fact that the retrieved context doesn't contain an answer. Prompt engineering helps. Confidence scoring helps. But we haven't fully solved this.
Where RAG Is Heading
The field is moving fast. Here's what I'm paying attention to:
Multi-Step and Recursive Retrieval
Instead of one retrieve-then-generate cycle, newer architectures run multiple rounds. The model reads the initial results, identifies gaps in the information, formulates follow-up queries, retrieves more information, and then generates. Think of it as giving the AI the ability to "research" a topic rather than just grabbing the first thing it finds.
We've been experimenting with this approach, and the quality improvement on complex, multi-faceted questions is substantial. The latency cost is significant though—you're essentially multiplying your retrieval time by the number of rounds.
Self-Reflective RAG
This is the one I'm most excited about. Systems that can assess their own confidence and decide when to retrieve versus when to answer from parametric knowledge. If the model is confident about a well-established fact ("What's the capital of France?"), it skips retrieval entirely. If it's uncertain, it triggers a search.
The practical benefit is huge: lower latency for simple questions, better accuracy for hard ones. We're watching the research here closely.
Multi-Agent RAG
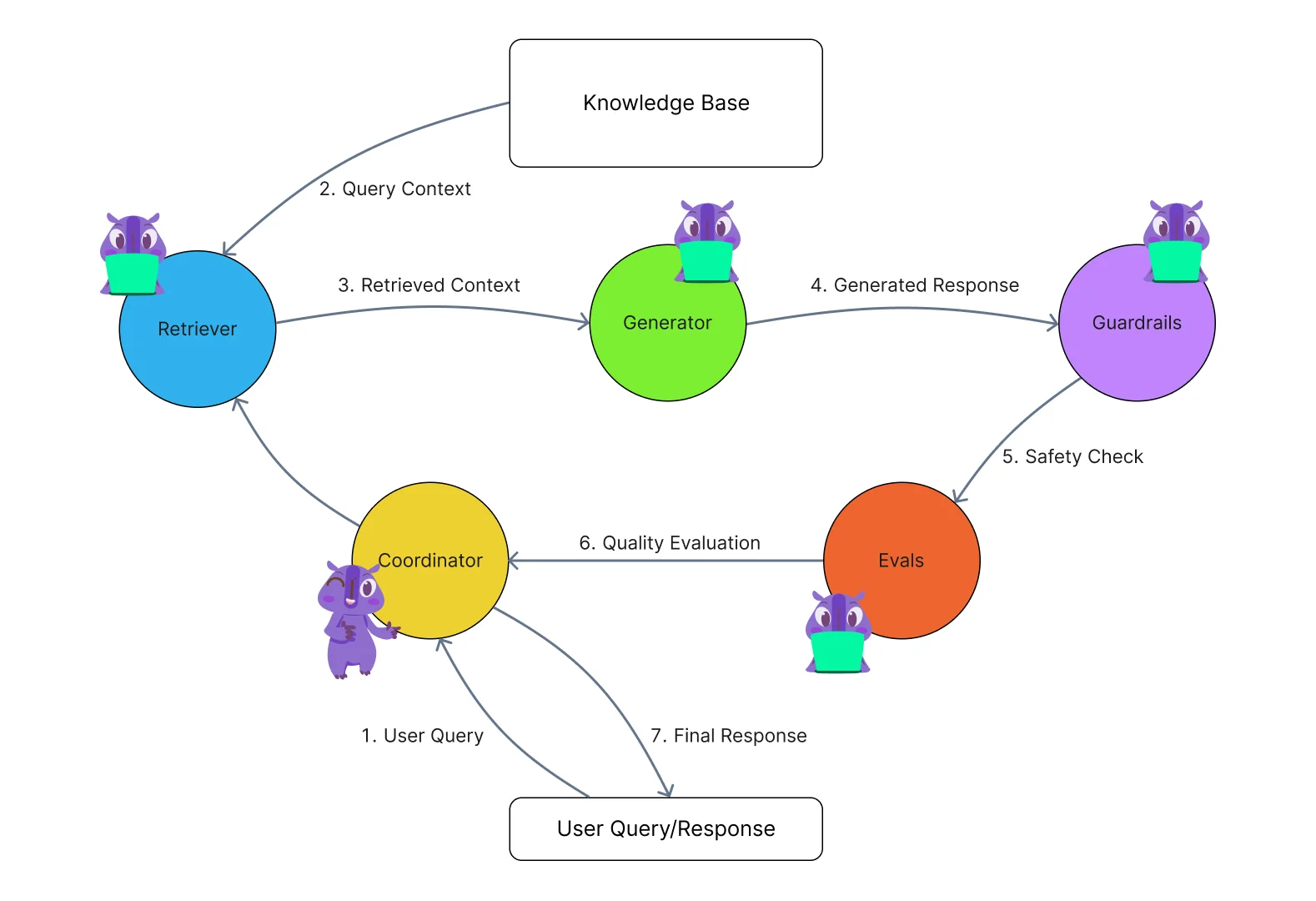
Instead of a single pipeline, you spin up multiple specialized agents—one for retrieval, one for fact-checking, one for synthesis, maybe one for deciding which knowledge base to search. Each agent handles its piece and they coordinate to produce the final answer.
It's complex to build, but the modularity is appealing. You can upgrade individual components without rebuilding the whole system. And specialized agents can be much better at their narrow tasks than a single general-purpose pipeline.
Multimodal Retrieval
Right now, most RAG systems work with text. But the information people need often lives in images, diagrams, spreadsheets, and videos. Multimodal RAG—retrieving across different data types and synthesizing them together—is the next frontier.
We've started experimenting with this for product screenshots and architectural diagrams. The results are promising but early. The embedding models for non-text content are improving rapidly, though, so I expect this to become practical within the next year.
The Honest Bottom Line
RAG isn't a silver bullet. I want to be clear about that.
It doesn't eliminate hallucinations entirely—it reduces them. It doesn't make LLMs smarter—it makes them better informed. It doesn't work out of the box—it requires real engineering effort to get right.
But here's the thing: it works. Practically, measurably, in production. We use RAG internally. We've helped teams implement it. And every time, the before-and-after difference in answer quality is dramatic enough that nobody wants to go back.
If you're building anything with LLMs that needs to be factually reliable, RAG isn't optional. It's the baseline. The question isn't whether to implement it—it's how to implement it well.
The teams that will get the most out of this technology are the ones that treat their knowledge base as a first-class product, invest in retrieval quality (not just generation quality), and build the monitoring infrastructure to catch when things go wrong. Because they will go wrong. But with a well-built RAG system, they'll go wrong a lot less often.

Read more about GEO, AI Search & Testing
5 Best AI Agents in 2025 (and How to Keep Them Reliable)
In this article, we'll take a look at the 5 best AI agents for 2025 and discuss why testing them is necessary to protect customer trust and satisfaction.
What ChatGPT Ads mean for brand visibility in AI conversations
ChatGPT is testing ads, but AI answers remain independent. What this means for brand visibility, trust, and winning in AI-driven discovery.
AEO vs GEO: What's the Difference and Why It Matters
Explore the difference between Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO), and why AI recommendations beat visibility