Genezio vs Profound: Which AI Visibility Platform Actually Gets You Recommended?
Genezio vs Profound and the rest: how to choose an AI visibility platform that increases AI recommendations, not just mentions. Buyer framework + pricing.

Most AI visibility tools on the market are good at one thing: telling you whether your brand showed up in an AI answer. Then they stop.
The problem is that showing up and being recommended are not the same event. ChatGPT can mention your brand in a list of eight options and still steer the buyer toward a competitor in the next sentence. That mention counts as "visibility" in almost every tool. It does nothing for your pipeline.
So when a marketing leader asks me "Genezio vs Profound: which AI visibility platform should we buy?", the real question underneath it is sharper: which tool actually changes whether AI recommends you? That distinction is where the buying decision gets made, and it's the axis this comparison is built on.
To be fair, recommendation measurement used to be a gap for Genezio too. A few months ago we put serious focus on it, because we kept seeing brands with strong visibility scores losing every "best [category]" answer to a competitor. This article is what we learned, turned into a buyer's framework you can run this week.
The quick verdict
Here is the short version for anyone who reads one paragraph before forwarding this to their team.
AI visibility is whether your brand appears in AI answers. AI recommendation is whether the AI tells the buyer to choose you. They correlate loosely and diverge often. A brand can have high visibility and a low recommendation rate, which means it's present in the conversation and losing it. If you only need to know whether you're showing up, most tools will do. If you need to know whether you're winning, and what to change when you're not, you need a platform built around recommendation, not mentions.
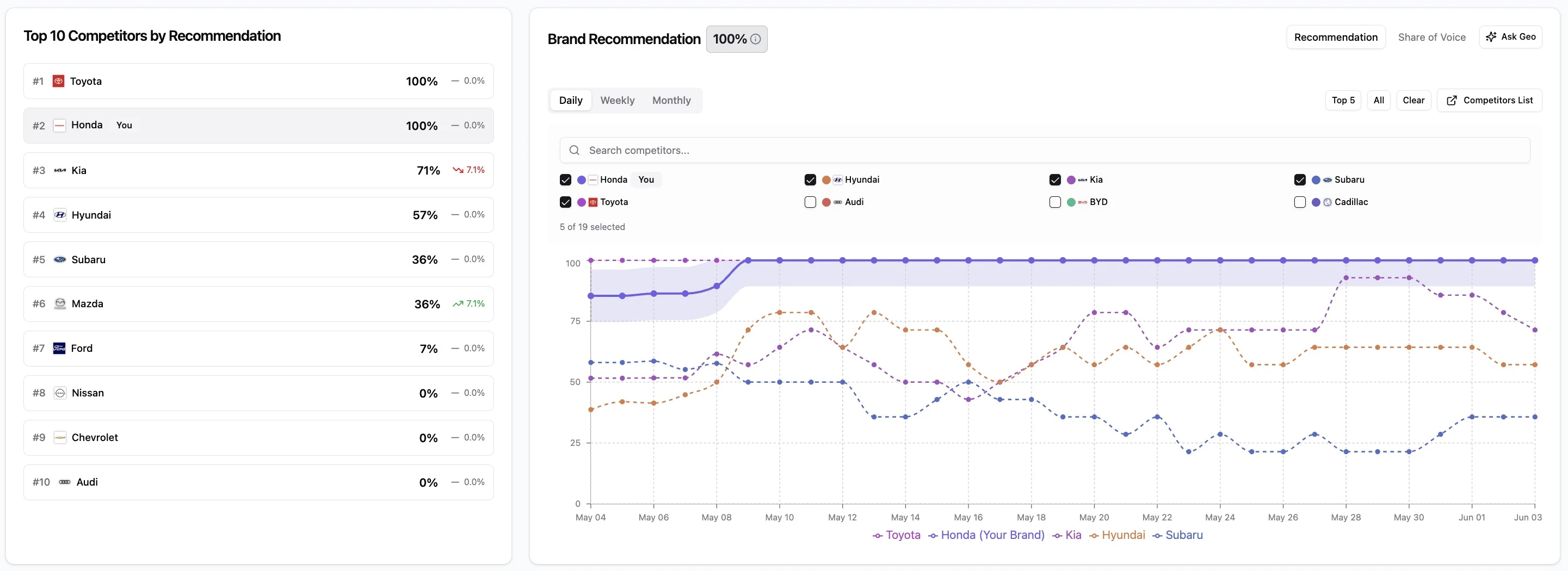
Decision rules:
- Choose Genezio if your KPI is how often AI recommends you versus competitors, you want that number with statistical confidence, and you want a prioritized list of actions to move it. Built for marketing and PR teams that have to prove impact and act on it.
- Choose Profound if you want a broad answer-engine analytics suite with panel-derived prompt demand data and built-in content generation agents, and you have the budget and analyst time to work the dashboards.
- Choose Semrush or Ahrefs if you already live inside their SEO suite every day and want baseline AI-mention monitoring bolted onto your existing workflow, not a recommendation-optimization program.
| Tool | Best for |
|---|---|
| Genezio | Recommendation-first measurement + an executable action plan |
| Profound | Answer-engine analytics, prompt demand data, content agents |
| Semrush / Ahrefs | AI-mention monitoring as an add-on to an existing SEO suite |
| Peec AI / OtterlyAI | Lower-cost prompt tracking and competitive visibility |
Why visibility is not recommendation
Here is the scenario every B2B marketer should test. A buyer asks ChatGPT, "What's the best project management tool for a 200-person agency?" Your brand appears in the answer. Your visibility tool logs a win.
Read the actual sentence, though. The model wrote: "Tools like Asana, Monday, and [your brand] are options, but for an agency that size, most teams go with Asana for its workload views." You were visible. You were not recommended. The buyer just got pointed somewhere else.
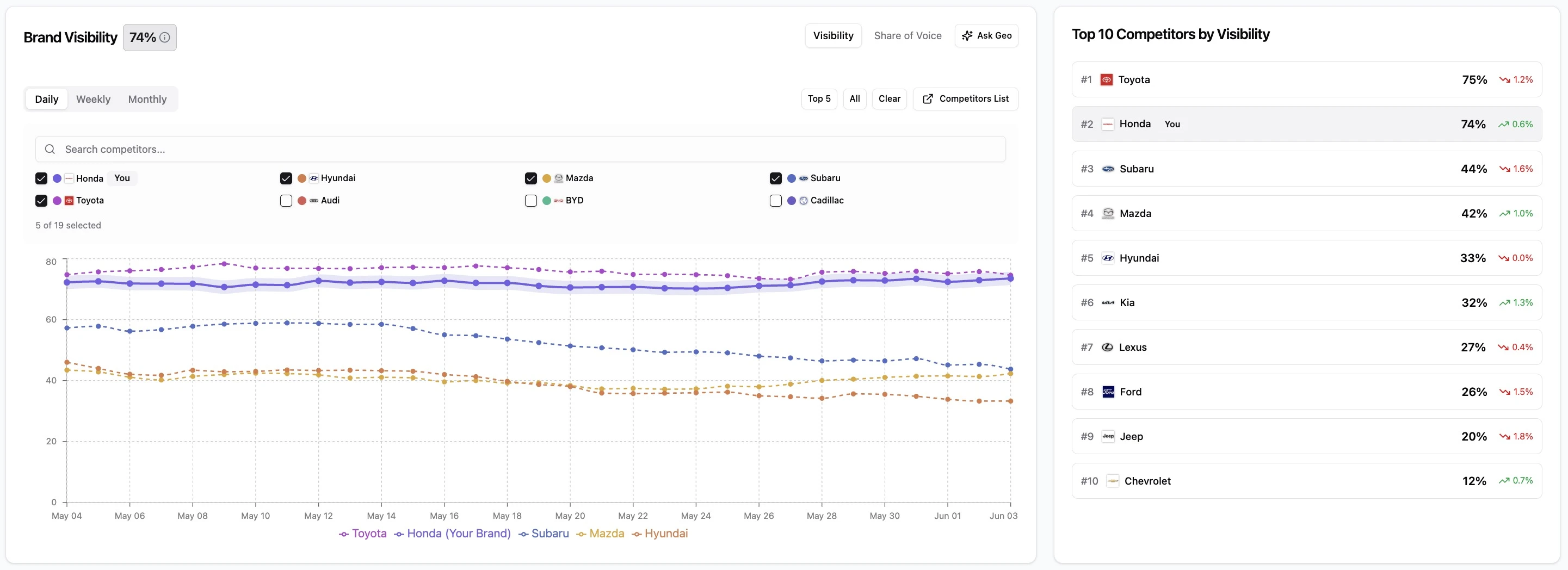
This is the trap: Visibility ≠ Recommendation. High visibility with a low recommendation rate is arguably worse than being invisible, because it feels like progress on a dashboard while you keep losing the decision. The goal isn't to be mentioned more. It's to optimize your presence to win more recommendations.
Two things separate a recommendation number you can trust from a vanity metric.
The first is how the answer is generated. We don't run a prompt once and record the result. We simulate full multi-turn conversations as your actual customer personas, a developer evaluating tools behaves differently from a procurement lead, and the recommendation flips depending on which one is asking and how the conversation unfolds across turns. A single prompt is a snapshot. A conversation is how buyers actually behave.
The second is sample size. Run a brand through 1,000 conversations and you get noise. Run it through 100,000 and you can report a recommendation rate as 73.2% ± 4.1%, a real percentage with a confidence interval, not a vibe pulled from a handful of queries. That's the difference between a metric you can take to your CEO and one you have to apologize for.
How to choose an AI visibility tool: a weighted scorecard
Don't pick on feature count. Score against what actually drives the outcome you're accountable for. Run this with your SEO, content, and PR leads in a 30-minute workshop, weight each row to your context, and score every shortlisted tool 1–5.
| Criterion | Why it matters | Weight |
|---|---|---|
| Recommendation measurement | Whether the tool measures recommendation, not just mentions | 25% |
| Statistical rigor | Confidence intervals and sample size behind every number | 15% |
| Engine coverage | ChatGPT, Google AI Overviews, Perplexity, Claude, Gemini | 10% |
| Persona / prompt strategy | Multi-turn persona conversations vs single-prompt checks | 10% |
| Action recommendations | Prioritized, specific actions vs generic observations | 15% |
| Citation & source analysis | Which publishers shape the AI's narrative about you | 10% |
| Perception analysis | Sentiment, extracted brand values, factual accuracy, SWOT | 5% |
| Reporting / exports / API | Stakeholder reporting and data portability | 5% |
| Security & multi-brand | SOC 2, SSO, multiple brands, roles and permissions | 5% |
Ten demo questions worth asking every vendor on your shortlist:
- Do you measure recommendation rate or only visibility? How do you define each?
- How many conversations sit behind a single brand's score, and what's the confidence interval?
- Are these single prompts or multi-turn conversations? Can I configure personas?
- Which engines are included on my plan versus locked behind enterprise?
- When my recommendation rate drops, what specific actions does the tool give me?
- Can you show which sources the AI cites when it recommends a competitor over me?
- Can you detect when an AI states something factually wrong about my brand?
- How do exports, scheduled reports, and API access work?
- SOC 2 Type II? SSO? How many brands and seats are included?
- What does the per-prompt, per-seat, and per-engine cost look like at the coverage I actually need?
Genezio vs Profound: Feature Comparison
Both platforms are serious. They optimize for different jobs.
Profound
Best for: Enterprise teams that want a full answer-engine analytics stack and have the budget and analyst time to run it.
Key strengths: Answer Engine Insights, Prompt Volumes (panel-derived demand data, a genuine strength most tools don't have), Agent Analytics for AI crawler and traffic interpretation, and Agents for content generation. Strong historical, time-series reporting.
Limitations: Built around visibility and share of voice, not a recommendation KPI. The $99 Starter plan covers ChatGPT only with 50 prompts and one seat; meaningful multi-engine coverage starts at the $399 Growth plan, which still caps at 100 prompts and a single region. Action guidance leans toward content generation rather than a prioritized cross-channel backlog.
Pricing signals: Starter $99/mo, Growth $399/mo, Enterprise custom (10+ engines, SSO/SAML, SOC 2, API). Prices current as of June 2026.
Ideal team: Enterprise marketing org with dedicated analysts running an AEO program.
Genezio
Best for: Marketing and PR teams whose KPI is being recommended, and who need to act on the result.
Key strengths: Recommendation rate as the primary metric, measured through multi-turn persona conversations at scale with confidence intervals. Competitive benchmarking on recommendation over time. Citation and source analysis tied to narrative accuracy. Direct AI perception analysis, branded questions, extracted values, sentiment, SWOT, and detection of factual misrepresentation. Prioritized action recommendations across website, content, and citations: actionable strategies, not just data.
Limitations: Genezio is not a content-generation engine. It tells you precisely what to fix and in what order; It can help you with briefs and drafts, but your team or your agency does the writing. If all you want is the cheapest possible mention tracker, that's not what this is built for.
Pricing signals: Quote-based, with enterprise plans including SOC 2 Type II and multi-brand management. Talk to the team for coverage-based pricing.
Ideal team: Mid-market to enterprise brand that has to defend a recommendation number to leadership and turn it into a backlog.
| Capability | Genezio | Profound |
|---|---|---|
| Primary KPI | Recommendation rate (with confidence intervals) | Visibility / share of voice |
| Competitive benchmarking | Yes, on recommendation over time | Yes, on visibility |
| Persona segmentation | Multi-turn persona conversations | Primarily single-prompt tracking |
| Citation / source analysis | Yes, tied to narrative accuracy | Yes |
| Action recommendations | Prioritized actions: web, content, citations | Opportunities panel + content Agents |
| Prompt discovery | Persona-driven scenarios and topics | Prompt Volumes (panel-derived demand) |
| Agent / content workflows | No (action briefs, not generation) | Yes (content generation agents) |
| Perception analysis (values, sentiment, SWOT) | Yes | Partial (sentiment) |
| Exports / API | Yes | Yes (higher tiers) |
| Security / compliance | SOC 2 Type II, multi-brand | SOC 2, SSO on Enterprise |
The honest read: if you want demand data and a content generator inside one analytics suite, Profound has real depth. If your problem is that AI keeps recommending someone else and you need to know why and what to do about it, that's the axis Genezio is built on.
How Genezio compares to Semrush, Ahrefs, Peec AI, and OtterlyAI
The wider market splits into two types. SEO suites that added AI features, and dedicated GEO platforms. Knowing which type you're evaluating matters more than any single feature.
| Tool | Type | Strength | Limit | Choose when | Pricing signal (June 2026) |
|---|---|---|---|---|---|
| Semrush (AI Visibility Toolkit) | SEO suite add-on | Lives inside your existing Semrush workflow | Mention monitoring, not recommendation optimization | You already run Semrush daily | $99/mo per domain (25 prompts); Semrush One bundles from $199/mo |
| Ahrefs (Brand Radar) | SEO suite add-on | Huge search-backed prompt database, broad research | Add-on cost stacks fast; directional, not action-first | You're deep in Ahrefs and want breadth | Base Ahrefs from $129/mo + $199/mo per AI index, or $699/mo for all six engines |
| Peec AI | GEO specialist | Clean prompt tracking, unlimited seats | Monitoring-focused, light on what to do next | You want straightforward competitive visibility | $95 / $245 / $495 per mo (50 / 150 / 350 prompts) |
| OtterlyAI | GEO specialist | Cheapest entry point, fast setup, GEO audits | Budget monitoring; thinner on strategy and engines | You want low-cost monitoring to start | $29 / $189 / $489 per mo (15 / 100 / 400 prompts) |
| Genezio | GEO specialist | Recommendation KPI, persona conversations, action plans | Not a content generator | You need to win recommendations and act on it | Engine, market & volume-based pricing |
The suites are great if your team already uses them and you want a baseline. They tell you when you appear. They were not built to tell you whether you were recommended, why a competitor was chosen, or what to do this week to change it.
A 30-day pilot to prove it
You don't need a six-month commitment to test any of this. Run a focused pilot and let the recommendation number decide.
- Week 1: Baseline. Pick your top 2-5 buyer prompts and a competitor set. Measure your recommendation rate and theirs across ChatGPT, Google AI Overviews, Perplexity, Claude, and Gemini. This is your starting line.
- Week 2: Citation gaps. Identify the sources the AI cites when it recommends competitors over you. Fix three content pages and your structured data so the right sources can find and cite you.
- Week 3: Narrative and PR. Correct any factual misrepresentations the model is repeating about you. Target two or three high-cited publishers for outreach or fresh content.
- Week 4: Re-measure and report. Re-run the same prompts. Report the change in recommendation rate, not just visibility, to your stakeholders.
Success criteria: a measurable lift in recommendation rate on your priority prompts, a shrinking gap to your top competitor, and a backlog of dated, owned actions. One client of ours added a single question to their onboarding flow as part of this kind of loop; AI attribution went from single digits to 36% in one quarter. The point of the pilot isn't a prettier dashboard. It's proof the number moves when you act.
FAQ
What's the difference between GEO and AEO? GEO (Generative Engine Optimization) and AEO (Answer Engine Optimization) describe the same broad goal, being present and chosen in AI-generated answers. The practical question isn't the label; it's whether a tool measures recommendation or only mentions.
Which AI engines should I track first? Start where your buyers already are: ChatGPT and Google AI Overviews for reach, Perplexity for research-stage buyers, then Claude and Gemini. Watch for plans that lock the engines you need behind enterprise tiers.
How many prompts do I need to track? Enough to cover your real buyer questions, not a round number. Twenty-five to fifty high-intent prompts is a solid pilot. What matters more is how many conversations run behind each prompt, because that's what gives the score a confidence interval instead of a guess.
Can I just measure AI traffic in my analytics? Mostly no, and this is where teams get a false sense of security. GA4 routinely shows a fraction of a percent of traffic from AI. When we pulled one client's server logs, the real number was orders of magnitude higher than GA4 reported. Analytics undercounts AI conversations badly, which is exactly why measuring recommendation directly matters.
Do SEO tools replace a GEO platform? For baseline mention monitoring, an SEO suite add-on is fine, especially if you already use it. For recommendation optimization, perception analysis, and a prioritized action plan, a purpose-built GEO platform does what a suite add-on wasn't designed to do.
How does Genezio measure recommendations? By simulating multi-turn conversations as your configured customer personas, across engines and geographies, at a sample size large enough to report a recommendation rate with a confidence interval, then mapping the gaps to specific actions on your website, content, and citations.
The brands that win the next two years won't be the ones that got mentioned the most. They'll be the ones that noticed when AI started recommending a competitor and did something about it before the quarter closed. If that's the number you're accountable for, that's the number Genezio is built to move. Book your demo to see it in action.
Pricing note: All competitor pricing verified against current vendor and review sources as of June 2026. Ahrefs Brand Radar in particular changed from earlier flat pricing to a per-index/bundle add-on model.

Read more about GEO, AI Search & Testing
Genezio vs Ahrefs Brand Radar: Big Data Doesn't Mean the Right Data
Ahrefs Brand Radar measures AI visibility, but Genezio measures AI recommendations. Learn why big data isn't always the right data for your GEO strategy.
Genezio vs. Peec AI: A Comprehensive Comparison for Marketers
Looking for Peec AI alternatives? Discover how Genezio goes beyond static monitoring to track real user journeys, multi-turn conversations, and hidden queries.
AEO vs GEO: What's the Difference and Why It Matters
Explore the difference between Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO), and why AI recommendations beat visibility