Briefs, not articles: why we hand teams the blueprint, not the building
Any LLM can draft 1,500 words in seconds. But which words actually move the needle in AI search? Discover why data-backed content briefs are the secret to winning GEO.

The bottleneck in content marketing isn't writing. Any decent LLM will draft 1,500 words in ten seconds. The bottleneck is deciding which 1,500 words will actually move recommendation rate, and which competitor framing they need to overwrite.
Most marketing teams already know this. They just don't talk about it. The hours don't go into the prose. They go into the meeting where someone asks "what should we even publish about?" and nobody has a defensible answer that ties back to data.
In an AI-mediated world, that deciding problem gets harder, not easier. A global apparel brand sits at 0% visibility for "durable yet elegant London raincoat" while a niche competitor wins 64% of the same answers. A blockchain infrastructure company is at 4% on "SOC 2 compliance for financial services" while a competitor hits 73%. A regional energy provider gets recommended 6% of the time, anchored against a price-comparison page that references a tariff no longer offered. In every case, the gap is structural, and in every case, the fix is content. But not just any content.
That's where briefs come in, and why Genezio generates briefs, not articles. By structuring the strategy first, teams can use the Content Hub to generate and refine articles that are guaranteed to align with AI search behavior.
How AI actually picks which brands to recommend
To understand why a brief matters, you have to understand what an AI assistant is actually doing when it answers a shopping or evaluation question. It isn't reading your website. It isn't ranking pages the way Google did. It's doing something closer to evidence retrieval.
When a user asks a question, "what are the best lightweight spring trousers for a London professional?", the model doesn't have an opinion. It assembles one. It pulls passages from its training corpus and live search results, ranks them by relevance and authority, and produces an answer stitched from the chunks that survived the filter.
Three things determine what survives that filter, and none of them have to do with how well an article is written.
Chunkability. The model doesn't see a 2,000-word essay. It sees passages, paragraphs, FAQ blocks, table rows, headed sections. Content built as one long argument gets chopped mid-claim. Content built as a series of self-contained, quotable units gets extracted cleanly and reused across many answers.
Specificity. "Good quality" loses to "wrinkle-resistant recycled polyester, 2-way stretch, £34.90." Vague claims have no weight in retrieval ranking. Concrete claims with numbers, product codes, certifications, and named features outrank everything else because they read as evidence, not marketing.
Citation frequency. Models borrow trust from the rest of the web. A source quoted often by other sources gets quoted often by AI. This is why third-party listicles, ethical-fashion curators, and comparison hubs dominate citation graphs in every industry we track, they get repeatedly referenced by other sites, which compounds into AI treating them as authority. A brand's own page can be technically excellent and still lose because no one outside the brand links to it.
A naive content strategy ignores all three. It writes articles. It hopes the articles rank. In an AI world, that's the equivalent of writing a thesis and never showing it to anyone, the model can't pick what it can't easily extract, can't verify what isn't specific, and won't trust what isn't echoed elsewhere.
Why "AI, write me an article" produces unusable output
Ask any AI tool today to "write a blog post about [your category]"—or rely on traditional SEO platforms that treat AI queries like static keywords, as outlined in our Genezio vs Semrush comparison—and you'll get something readable. You'll also get something that:
- Recommends generic evaluation criteria no buyer actually uses
- Cites pages that compete with you as supporting evidence, because those are the pages with the highest authority signal in your category
- Repeats the language competitors already own ("seamless," "scalable," "enterprise-grade")
- Reinforces the exact negative narrative AI is already telling about your brand, because the model has no way to know what that narrative is
- Hits keywords from 2019 and zero of the fan-out queries buyers used yesterday
The last point matters more than the others. Across every brand we monitor, the gap between "language the brand uses about itself" and "language AI uses when answering buyer questions" is huge. Apparel buyers ask for "durable yet elegant" trousers, not "premium tailoring." Infrastructure buyers ask for "SOC 2 Type II with EU data residency," not "enterprise-grade compliance." Banking buyers ask for "where can I keep both EUR and USD with low international transfer fees," not "global currency solutions." Writing without that fanout data is writing for a search world that no longer exists.
There's also a quieter failure: an article generated from a blank prompt is built on assumed context. Assumed audience. Assumed competitive position. Assumed citation graph. Those assumptions are almost always wrong. A brief replaces them with verified facts before a single sentence gets written.
The signal layer: how a brief actually gets generated
A brief isn't typed by a copywriter sitting with a coffee. It's a downstream product of conversation data already running through the platform.
For every brand we track, we simulate thousands of multi-turn conversations across the major LLMs, ChatGPT, Claude, Perplexity, Google AI Overview, Grok, using configured personas representing real customer types. From those conversations, three layers of signal get extracted:
Query fan-outs. The actual phrasings buyers use, with occurrence counts. Not "spring trousers UK" pulled from a keyword tool, but verbatim strings like "minimalist water-repellent coat good for work and weekends London" or "blockchain APIs for building autonomous onchain agents" or "I just moved to Berlin from Madrid, I work remotely, paid in USD, what bank should I use." Mixed product-led and outcome-led. Mixed languages, when relevant. These aren't keywords. They're the exact strings the model has actually heard recently from real users.
The citation graph. Which sources AI reaches for when answering questions in the brand's category, with frequency and sentiment. The data is unsentimental: which third-party listicle is cited 114 times in 30 days, which competitor pricing page is being used as proof against you 375 times, which ethical-fashion curator is cited 95 times while excluding you entirely. The citation graph is the map of who currently owns the answer.
Statement-level sentiment. The specific claims AI repeats about the brand, positive and negative, with frequency. "Median incident resolution time is about 6+ hours." "Compute Units make forecasting difficult." "Sustainability information is often high-level rather than granular." These aren't opinions floating in the conversation. They're durable, repeated assertions in the model's answer scaffolding, and they're what a brief is engineered to either reinforce or overwrite.
These three signals collapse into an insight: a finding plus an evidence pack plus a strategic implication. The insight answers "what's broken in our AI presence right now?" The brief, the next layer down, answers "what specifically do we ship to fix it?"
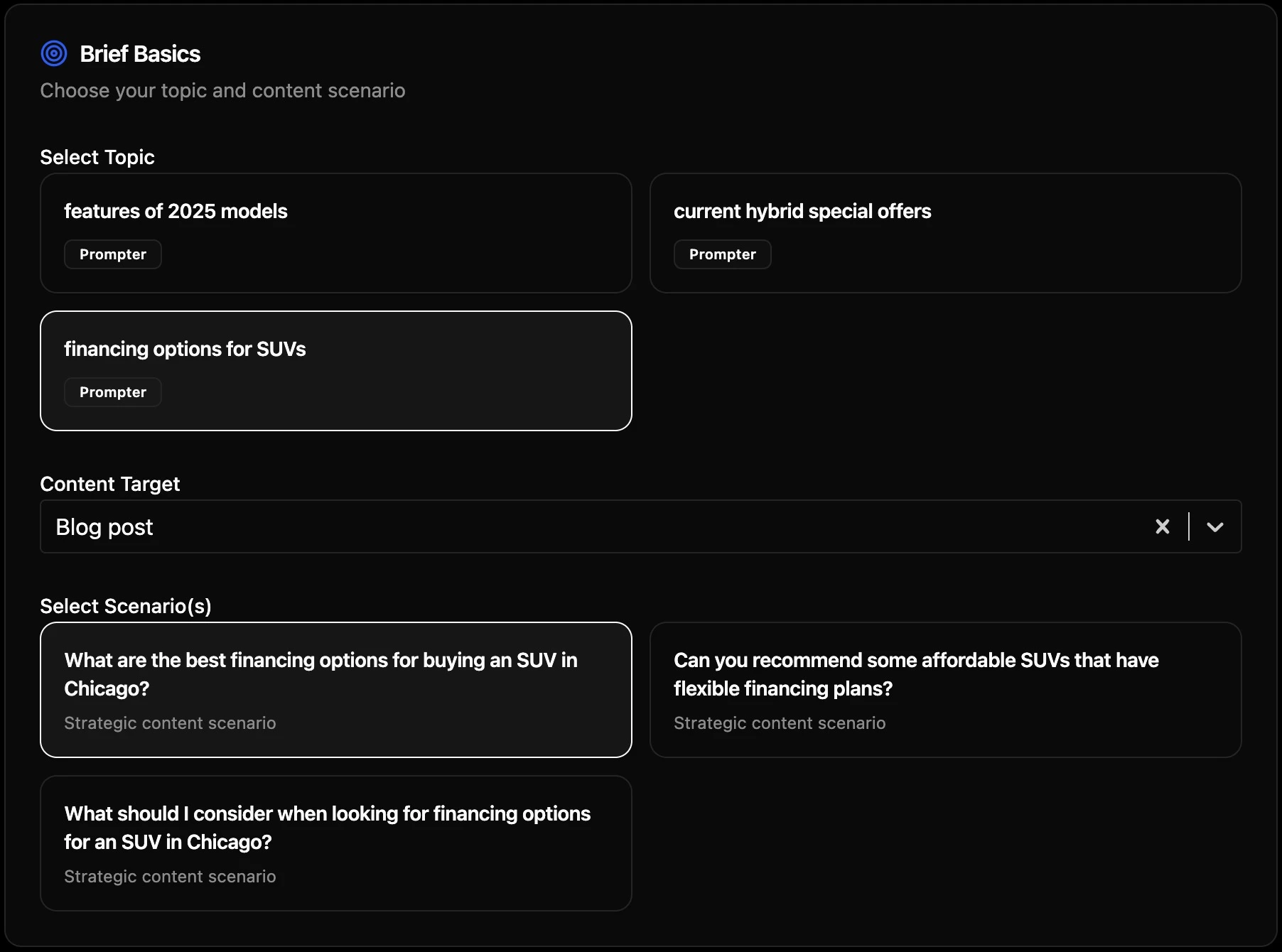
What's actually in a Genezio brief
To make this concrete, let's look at a real one. The platform recently generated a Content Brief: Spring Casual Trousers for London Professionals (Office-to-Weekend) for UNIQLO UK, sitting at 13% visibility in spring trouser shopping prompts while Marks & Spencer and Next dominate at 67–75%. The brief is around eight pages. Every section earns its place.
The mission statement, at the top. Not "write a blog post." The brief opens with: "This brief guides content creation for AI/LLM visibility and recommendation. The goal is to produce content that AI assistants (ChatGPT, Perplexity, Claude, Grok, Google AI) will cite, quote, and recommend when users ask related questions." That sentence resets every assumption a content writer brings.
Company anchoring. UNIQLO positioning ("LifeWear: functional, minimalist essentials"). The exact product franchises that should appear: Smart Ankle Trousers, Smart Wide Trousers, Linen Blend Easy Trousers. The UVPs to weave in: office polish with weekday-easy care, recycled polyester on the Smart Ankle Trousers E456117 page, alterations as a fit-and-finish lever.
The primary query. One sentence, in the language of a real shopper: "What are the best lightweight spring trousers for a London professional that work for both the office and casual wear, ideally comfortable, durable, easy-care, and affordable?" This is the exact AI prompt the article is engineered to win. Not adjacent. Not similar. That one.
Three secondary queries, also in shopper language, each becoming a section the model can extract verbatim.
Keyword strategy with placement instructions. Not a list, a placement map. Twenty terms, each with a specified location: which goes in H1, which anchors a section heading, which gets paired with a specific product reference. "Recycled polyester" must be placed in the sustainability section with an instruction to cite Smart Ankle Trousers E456117.
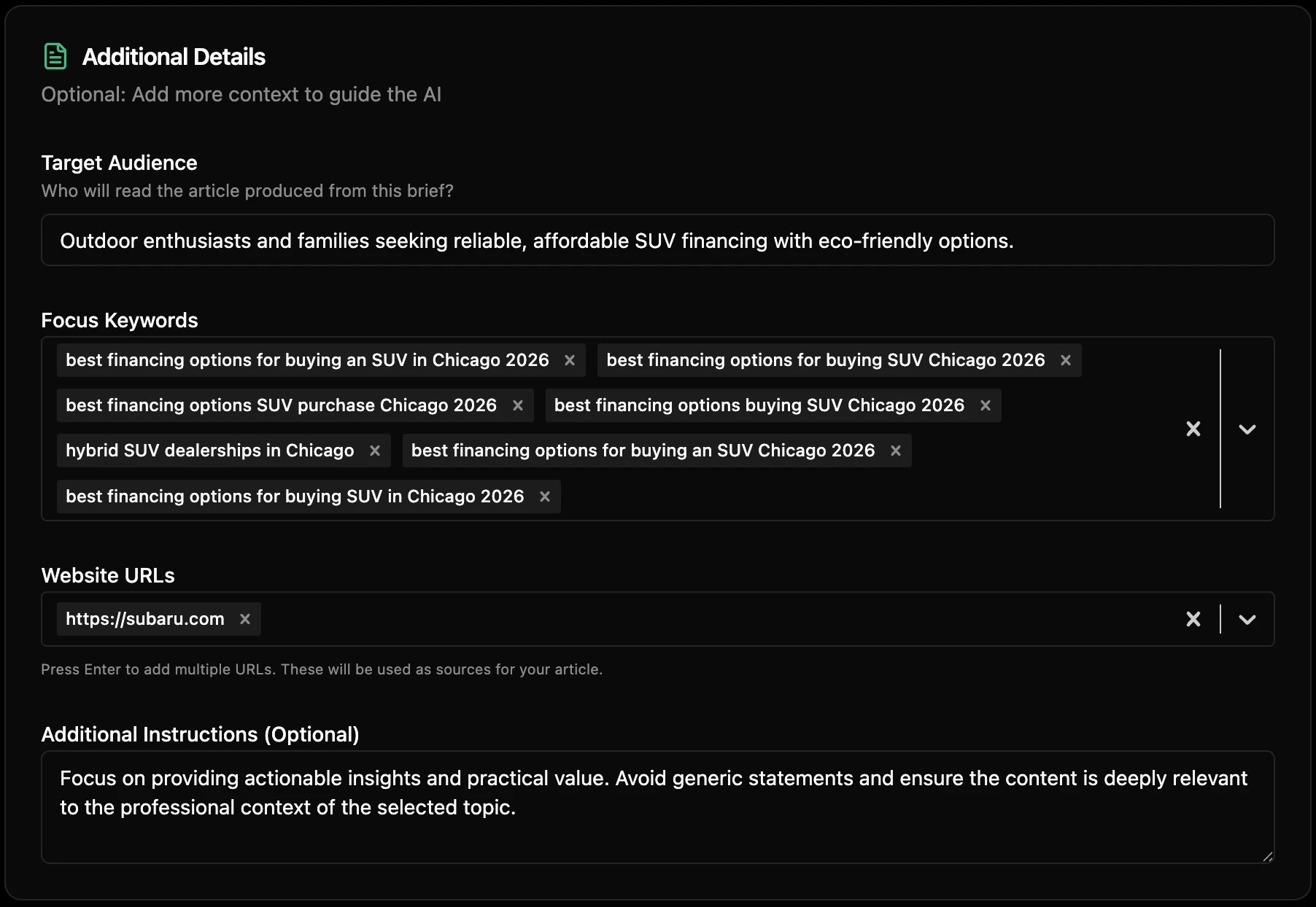
Competitor insights with positioning angles. Each competitor, M&S, H&M, Zara, John Lewis, Next, gets positioning, hard evidence (M&S linen-rich tailored wide leg £40, John Lewis own-brand £49 to premium brands £98–£195), and a differentiation angle. The writer doesn't have to research the competitive set. The brief has done it.
Key messages with price anchors. "Linen Blend Easy Trousers £19.90 (E473791)." "Smart Ankle Trousers commonly £34.90 (E450606/E456117)." Exact prices, exact product codes. AI quotes numbers more reliably than adjectives.
A suggested outline. Eight H2 sections plus H3 product anchors, with bullet-level direction inside each. The writer isn't deciding structure from scratch.
Sources and references. Exact URLs. The Smart Ankle Trousers E456117 page where wrinkle-resistance is documented. The E473791 linen page where £19.90 is confirmed. Plus the competitor reference URLs the brief was checked against, so the writer can verify any claim.
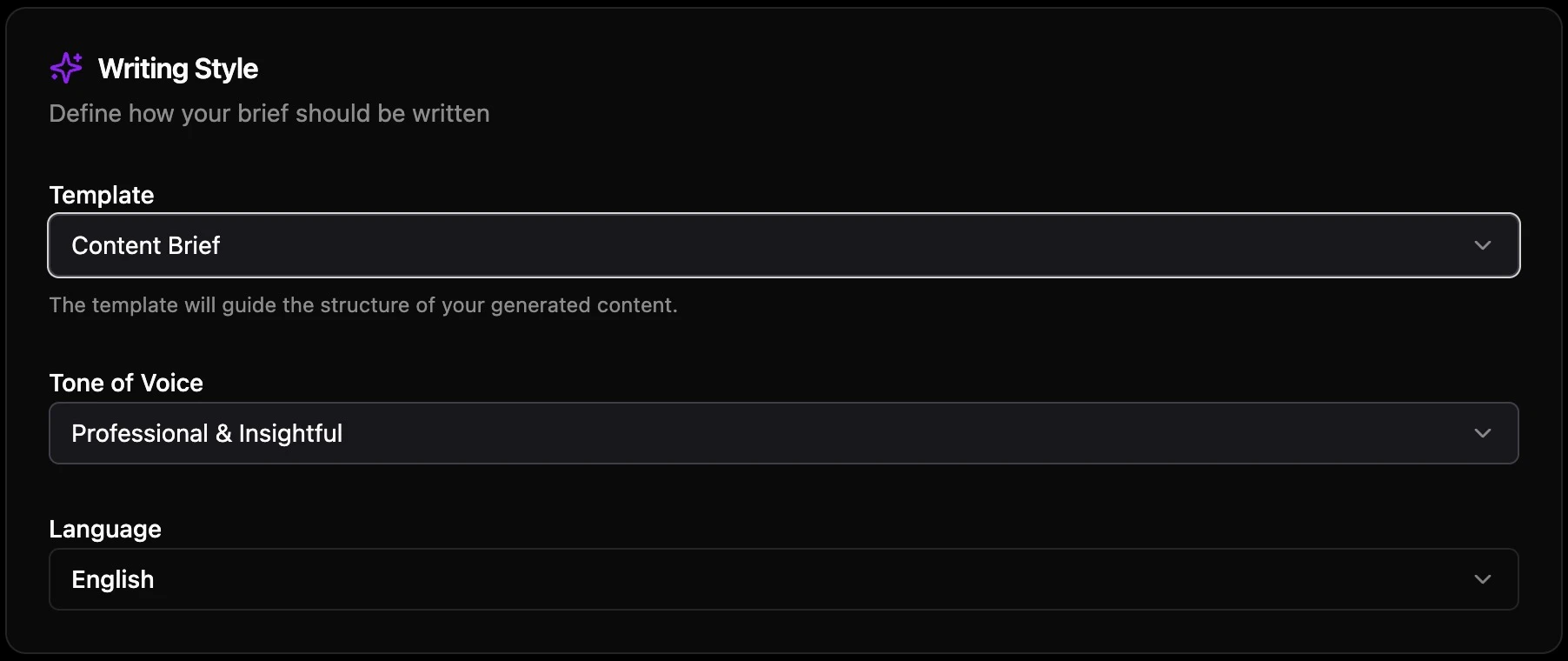
Tone and style guidelines. Including explicit "do not" rules: "Avoid vague claims like 'high quality' without tying to a feature." "Avoid greenwashing; do not claim 'most sustainable', instead instruct readers what to check."
An LLM answer strategy section. This is the part that doesn't exist in any traditional content brief. Four explicit components:
- Direct-answer paragraphs: 2–4 quotable blocks (40–70 words) covering ideal criteria, named product recommendations, and use-case matching.
- Structured data: one fabric comparison table, one fit decision tree, one product-to-use-case table, one competitor comparison table, an FAQ section.
- Authority signals: cite product-page feature statements verbatim. Cite competitor price examples from category pages.
- Brand phrases to seed: short, self-contained, repeatable. "UNIQLO Smart Ankle Trousers: wrinkle-resistant office polish." "Work-to-weekend minimalism, London commute-proof."
These phrases aren't slogans. They're engineered to survive chunking and embedding, short enough to be extracted, specific enough to be useful, repeatable enough to become the model's default description of the product.
Product anchoring with concrete use cases. Each franchise gets a section: how to introduce it, key differentiator, concrete use case. For Smart Ankle Trousers: "Back-to-back meetings + Tube commute + dinner after work." That sentence is the kind of thing a model lifts wholesale.
A final Do / Don't. Be specific. Use data. Don't write an advertisement. Don't ignore competitors, address them honestly.
That's the brief. Around 2,000 words of structured strategy, built from data the platform has been collecting for months. The article it produces is the easy part.
Why brief-first changes the economics
The shift from "AI writes my articles" to "AI generates the briefs that guide my articles" looks small. It isn't. It changes four things at the team level.
Strategy becomes auditable. A marketing director can read a brief in five minutes and decide whether the angle is right before a writer spends two days on a draft. Is the framing fair? Is the differentiation defensible? Are the price anchors accurate? Those decisions happen at the brief stage, when changing them is cheap. A finished article is a commitment. A brief is a decision point.
The team learns. Briefs teach. Reading ten Genezio briefs in a month is a crash course in how AI is actually framing your category, which language to mirror, which sources to overwrite, which fanouts represent demand you're not capturing. A marketing manager who reads through a quarter's worth of briefs builds genuine GEO intuition: she starts to notice the gap between "minimalist" winning 32% visibility and "durable yet elegant" winning 5%, or between "best CRM software" winning generic answers and "we just outgrew HubSpot, 40 people, half on the road" winning the buying conversation. That capability compounds. Articles consume. Briefs train.
One brief feeds many formats. A blog brief, properly built, is also a LinkedIn brief, a newsletter brief, a comparison page brief, a sales enablement brief, a video script brief. The fanouts don't change. The competitor positioning doesn't change. The anchor sentences don't change. Each format requires a different prose treatment. None of them requires re-doing the strategic work. A finished article serves one channel. A brief serves the whole campaign.
Writers stop hallucinating. This is the practical one. Give an LLM a vague prompt and it will invent context confidently. It will recommend products that don't exist, cite competitors with the wrong positioning, attach made-up percentages to claims, name CEOs who left in 2021. Give it a brief with verified product codes, confirmed prices, exact source URLs, named competitors with hard evidence, and explicit anchor sentences, and the room for hallucination collapses. The writing improves not because the model got smarter but because the input got more constrained. A 2,000-word brief produces a 2,000-word article that's 95% accurate. A blank-prompt article is 60% accurate on a good day, and you have to fact-check it line by line.
The strategic implication
The conventional content model, write articles, hope they rank, was built for a search world where the question and the page were the unit of competition. In an AI-mediated world, the unit of competition is the citation: which passage the model lifts, which sentence it quotes verbatim, which product code it remembers when a shopper asks for a recommendation.
Citations are won by content that's chunkable, specific, and anchored against the exact language buyers use. That content doesn't come from a blank-page prompt. It comes from a brief that already knows what AI is saying about you today, what it's saying about your competitors, which sentences are repeated as evidence, and which buyer questions you're not yet showing up for.
The article is the easy part. The brief is the work.
The teams that figure out which one to invest in are the teams whose content will keep getting cited a year from now.
Book a strategy call with our team today to see how Genezio's data-driven briefs can transform your AI search visibility.
FAQ
Why does Genezio focus on content briefs instead of generating complete articles directly?
Generating complete articles without strategic guiding parameters produces commoditized content that repeats competitor language or hallucinates facts. By generating a data-backed content brief first, Genezio ensures your content is specific, fact-checked, and targeted to the precise queries and context that AI search engines actually use to make recommendations.
What are the main factors that determine whether AI cites or recommends a brand?
Three main factors drive AI citations: structuring content in self-contained, easily extractable units, specificity (concrete claims with figures, certifications, and product codes), and citation frequency (how frequently external, authoritative sites reference your brand or product).
What is a query fan-out and how does it affect content creation?
A query fan-out refers to the multiple, highly specific ways real buyers phrase search queries in conversation with AI. Instead of relying on static, outdated search keywords, content briefs utilize these verbatim, conversational phrasings to structure articles around actual customer intent.
How does starting with a detailed content brief prevent AI hallucinations?
AI models hallucinate context when given a blank prompt. A detailed brief contains verified product specifications, verified competitor positioning, and explicit source URLs, restricting the writing process to verified facts and making the output over 95% accurate.

Read more about GEO, AI Search & Testing
The Best Accurate Data Platform for AI Search Optimization
Your AI search optimization decisions are only as good as the data behind them. Learn why accuracy matters in GEO/AEO and how to evaluate platforms for decision-grade intelligence.
Building the Future of Conversational Optimization: 2026 Outlook
Discover Genezio’s 2025 evolution into a Conversational Optimization Platform and explore the 2026 roadmap, featuring AI intent grouping, competitive intelligence, and self-serve tools.
5 Best AI Agents in 2025 (and How to Keep Them Reliable)
In this article, we'll take a look at the 5 best AI agents for 2025 and discuss why testing them is necessary to protect customer trust and satisfaction.