The Best Accurate Data Platform for AI Search Optimization
Your AI search optimization decisions are only as good as the data behind them. Learn why accuracy matters in GEO/AEO and how to evaluate platforms for decision-grade intelligence.

TL;DR
Your AI search optimization decisions are only as good as the data behind them. If your platform reports that ChatGPT mentions your brand in 60% of relevant prompts, but the methodology is opaque or the sample is too thin to trust, you're optimizing against noise.
Genezio is built for marketing leaders and enterprise buyers who need defensible, decision-grade data about how AI engines like ChatGPT and Google AI Overviews mention, cite, and recommend their brand. Here's what we've learned matters most for generative engine optimization (GEO): accuracy in this category has multiple dimensions, and most platforms are strong on the dimensions that don't differentiate while being weak on the ones that do.
This guide walks through both. If you're evaluating GEO/AEO platforms and the stakes include budget allocation, executive reporting, or competitive strategy, accuracy isn't a feature. It's the entire product.
Why "Accurate Data" Is the Core Question for AI Search Optimization
AI search optimization is at the stage every emerging marketing channel goes through. Vendors are multiplying, dashboards are proliferating, and the methodology behind the numbers varies wildly from platform to platform. Two tools tracking the same brand will produce materially different visibility scores, recommendation rates, and competitive rankings. Not because one is right and one is wrong, but because they're measuring different things using different methods.
For enterprise teams, this creates a specific risk. You report that AI recommendations for your brand grew 18% quarter-over-quarter. Your CMO asks how that number was calculated. If the answer is "the platform calculated it," you have a credibility problem. If the answer involves a defensible methodology, specific prompt sets representative of buyer queries, multiple AI engines tested with consistent sampling, transparent scoring rules, you have a decision-grade reporting layer.
The difference between these two states isn't a feature comparison. It's whether your AI visibility program can survive scrutiny.
Genezio is built around a simple recognition: accuracy in AI search data has multiple dimensions, and a platform is only as strong as its weakest one. Some dimensions are now table stakes that most credible platforms cover. The dimensions where platforms actually differ, and where buying decisions should be made, are measurement, multi-turn handling, persona segmentation, statistical confidence, and prompt relevance.
This guide focuses on what differentiates. The rest is noted briefly so you have the complete picture.
The Accuracy Dimensions That Differentiate Platforms
1. Measurement Accuracy
Measurement accuracy answers a deceptively simple question: are the metrics measuring what they claim to measure?
The most common failure in this category is conflating "mentioned" with "recommended." An AI engine might name your brand in a list of ten providers and still steer the user toward a competitor. A platform that reports both under a single "AI visibility score" hides the diagnostic information you need to actually improve outcomes.
A brand with 60% visibility and 12% recommendation rate has a specific, fixable problem: AI knows you exist but prefers competitors. The gap between those numbers, what we call the recommendation gap, is the most actionable diagnostic in AI search optimization. Aggregating them into a single score destroys that signal.
Genezio measures visibility and recommendation as distinct KPIs, with consistent scoring rules across engines. A mention is when your brand name appears anywhere in the response. A recommendation is when AI explicitly positions your brand as a solution, describes it substantively, or includes it among "top picks" rather than relegating it to an "other options include" caveat. These definitions are applied identically across ChatGPT, Perplexity, Claude, Gemini, and Google AI Overviews, which is what makes cross-engine comparison meaningful for your overall Answer Engine Optimization (AEO) strategy.
Why this matters in oligopoly markets. In categories dominated by a few established players, AI engines will almost always mention your brand. Visibility metrics flatten near the top and aggregate data starts to look misleadingly positive. The real competitive dynamic happens at the recommendation layer, where AI shifts which brand it actually endorses depending on the buyer context. A platform that reports a single aggregate recommendation rate hides this entirely. Separating visibility from recommendation surfaces the market intelligence that oligopoly competitors actually need: where the recommendation logic is shifting, even when visibility looks stable.
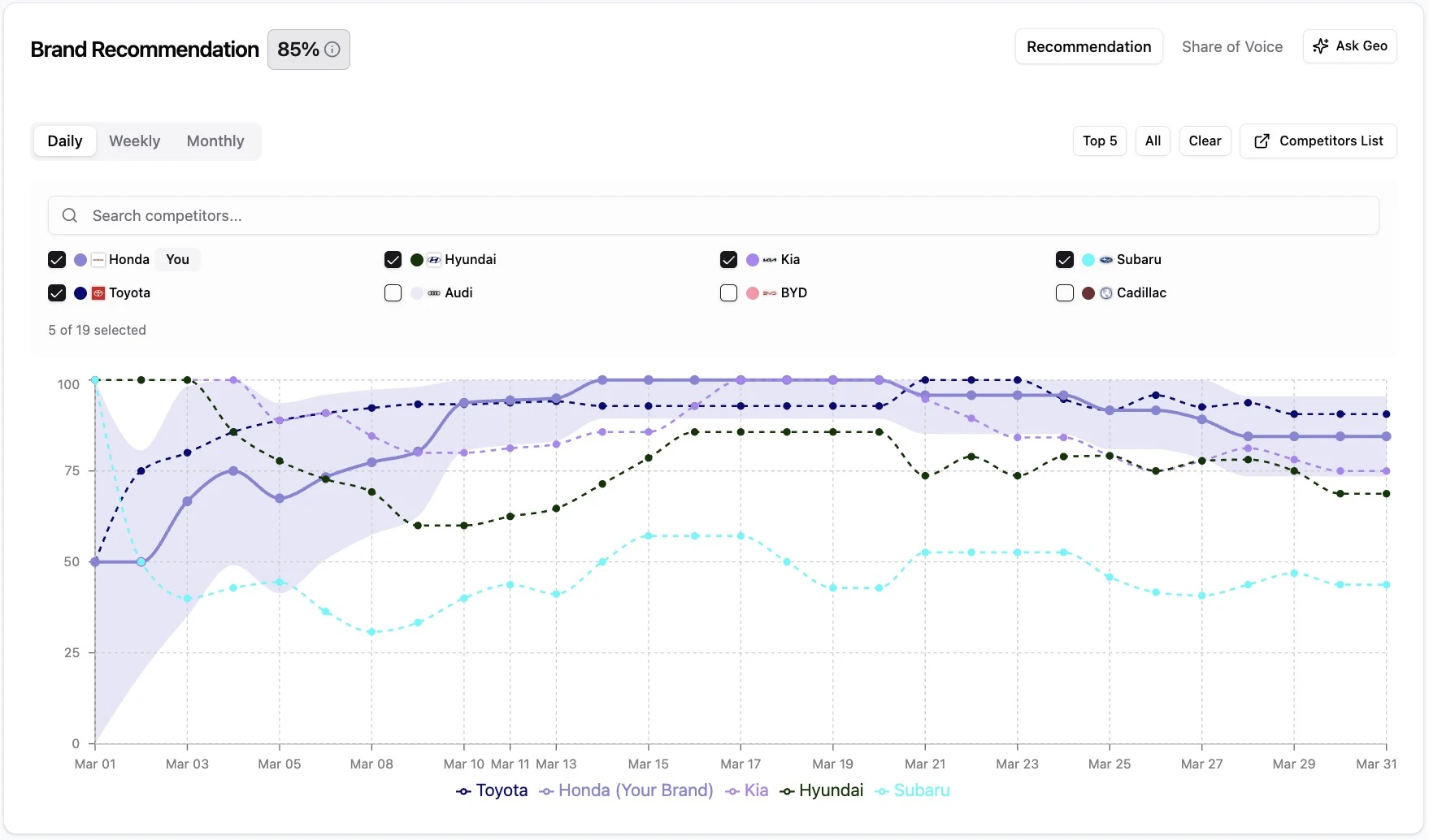
2. Multi-Turn Conversation Accuracy
Most platforms test prompts in isolation. One query, one AI response, one data point. It's convenient for measurement, but it doesn't reflect how buyers actually use AI engines.
Real buyer behavior is multi-turn. A buyer asks an initial question ("What's the best CRM for small businesses?"), gets a list of options, then refines: "Which has the best Salesforce integration?" or "Which is cheapest for teams under 10?" Each follow-up narrows the recommended set based on AI's understanding of each brand's specific attributes.
A brand that appears in the initial "top 5" but gets dropped after the first follow-up has a multi-turn problem that single-turn measurement won't reveal. The aggregate single-turn data tells you you're winning. The multi-turn reality tells you you're losing the deals that matter, the ones where the buyer narrowed in on the specific criteria that determine the purchase.
This is one of the most under-measured dimensions in the category. Most platforms operate on the implicit assumption that single-turn data is representative of multi-turn behavior. It isn't. In categories where buyers naturally drill into specific attributes (compliance, integration, pricing tier, persona needs), single-turn measurement consistently overestimates brand strength.
Genezio tracks how brand presence and recommendation status change across multi-turn conversation paths, not just at the initial query. It's significantly closer to how buyers actually use AI engines today, and significantly closer to the truth about which brand wins.
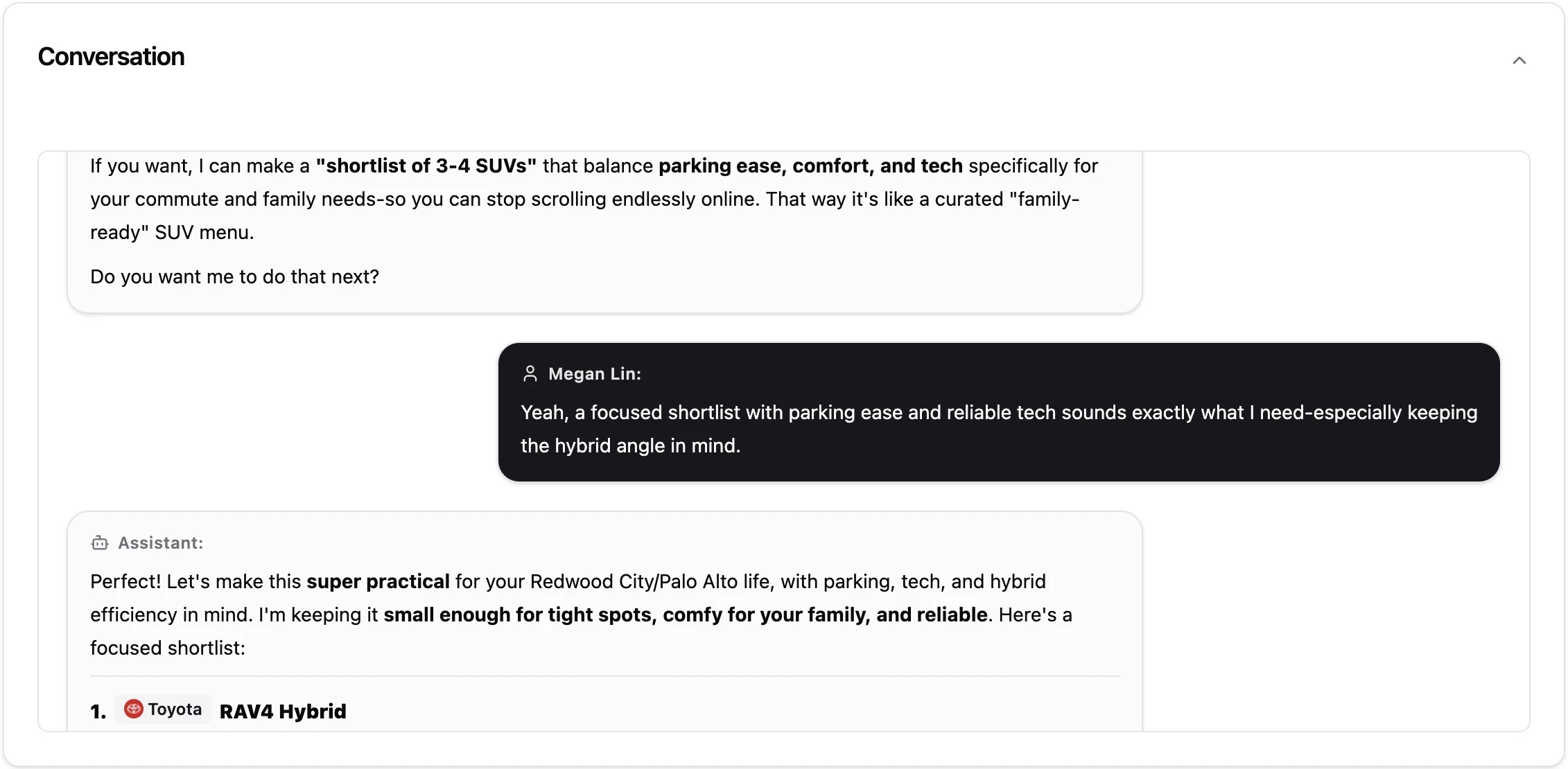
3. Persona Accuracy
The same prompt produces different AI answers depending on who's asking, and the differences are often strategically important. A "best [category]" query from a developer persona surfaces API capabilities and integration depth. The same prompt from a procurement persona surfaces enterprise pricing, compliance, and vendor support. The same prompt from an end-user persona surfaces ease of use and design quality.
If your product is technically excellent but procurement language is thin on your site, AI may recommend you to developers and recommend a competitor to procurement leads, even though both work at the same company evaluating the same purchase. Your aggregate recommendation rate looks fine. Your win rate at the procurement stage is the actual problem.
This matters most in complex B2B sales where multiple stakeholders influence the decision, but it applies broadly. Even consumer brands experience persona-driven variation. AI describes the same product differently to "young professional" vs. "value-conscious shopper" vs. "premium buyer" personas, and the recommendations follow.
Genezio's persona segmentation makes this granular. You can configure prompt variants for technical buyers, business decision-makers, end users, procurement teams, or any other segment relevant to your sales motion. The resulting data tells you not just whether you're being recommended, but to whom, and which personas need different positioning content to convert visibility into preference.
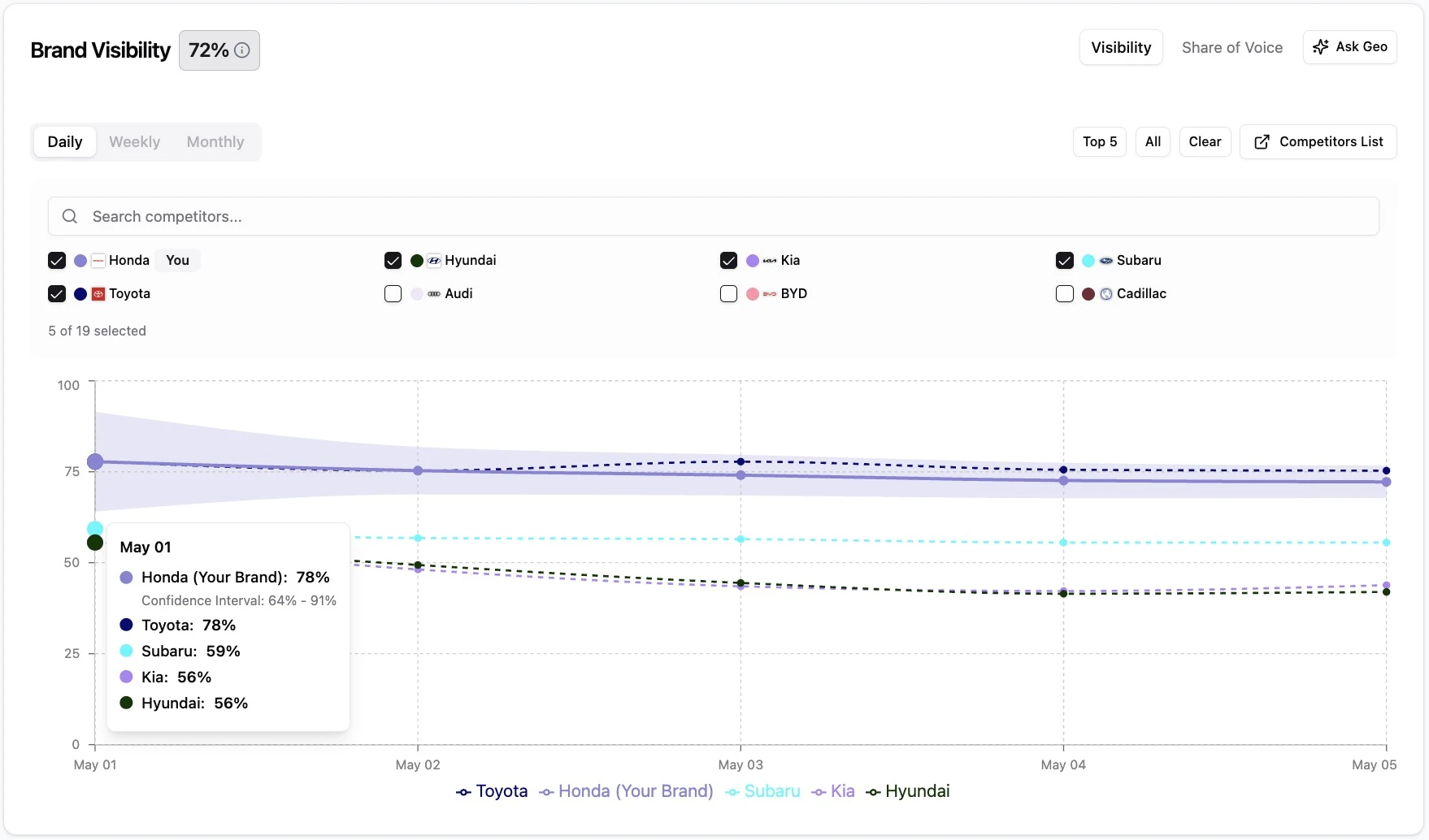
4. Statistical Confidence
Here's a question most platforms quietly avoid: how reliable is the number you're looking at?
AI search data has a structural property that makes naive metrics dangerous. Every prompt-engine combination is effectively a sample. A 50-prompt library across 5 engines produces 250 data points/day, meaningful at the aggregate level but unevenly distributed once you slice by persona, topic, or engine. Slice the data into a "recommendation rate for procurement persona on Perplexity for cloud infrastructure prompts," and you might be reporting a percentage based on 8 observations. That number is technically accurate. It's also statistically meaningless. A single AI response one way or the other moves it by 12 percentage points.
Platforms that report point estimates without confidence intervals create a specific failure mode: teams make confident decisions on noisy data. Your recommendation rate moved from 22% to 31% and you conclude your content launch worked. Without confidence intervals, you can't distinguish "real 9-point improvement" from "random variation in a small sample." Strategy gets built on artifacts.
Most platforms in the GEO/AEO category don't expose this. It's partly a design choice (confidence intervals make dashboards look less clean) and partly a methodological gap (the platform isn't actually modeling sample size and variance).
Genezio surfaces statistical confidence explicitly. As your prompt library runs, the platform tracks how many observations support each metric and how the certainty around that metric tightens as more data accumulates. Early in a monitoring program, when you have 50 prompts and one week of runs, confidence intervals are wide and the platform tells you so. As prompt sets expand and runs accumulate, intervals narrow, and the data becomes progressively more decision-grade.
For executive reporting, this is the dimension that lets you defend the data when challenged. "Recommendation rate moved from 22% (±5) to 31% (±3)" is a defensible statement. A bare point estimate isn't.
5. Prompt Relevance
The four dimensions above all assume you're testing the right prompts. Prompt relevance asks a more fundamental question: are the prompts you're monitoring actually meaningful for your category?
No amount of statistical rigor can fix this failure mode. You can have multi-engine coverage, recommendation-vs-mention separation, multi-turn tracking, persona segmentation, and tight confidence intervals, and still be optimizing against a prompt set that doesn't reflect your competitive reality.
The signal that reveals the problem is specific: a prompt that returns no brand matches, neither yours nor any defined competitor. This pattern is informative in two distinct ways, and the platform should help you tell them apart.
Signal 1: Your competitor set is incomplete. AI engines surface brands that match query intent. If a prompt about "best [category] for [use case]" returns five brands and none are on your competitor list, the most likely explanation is that you're missing real competitors from your benchmarking frame. The brands AI actually recommends are who buyers are actually choosing between, even if they weren't on your strategy team's radar. Internal competitor lists tend to over-index on direct historical rivals and miss adjacent players that buyers have started considering.
Signal 2: The prompt isn't relevant to your category. Sometimes a prompt is testing a need no one in your niche addresses. If neither you nor any reasonable competitor appears for an obscure use case, the prompt may be probing outside your category's natural answer space, or simply be poorly phrased. Continuing to monitor it adds noise without signal.
These two signals look identical at the surface (your brand and competitors are both absent), but they require opposite responses. Misdiagnosing them is costly. Expanding your competitor set when the prompt was the problem clutters your benchmarking. Pruning the prompt when your competitor set was the problem leaves you blind to emerging competitive threats.
Genezio's relevance scoring flags these cases automatically and helps you triage them. For each prompt that returns no brand matches, the platform surfaces what AI did return, and lets you decide whether to add discovered brands to your competitor set or edit/remove the prompt from your library. Over time, this creates a self-improving system. Your monitoring stays aligned with real category reality, not the assumptions you started with.
This dimension is one of the least discussed in the GEO/AEO category and one of the most consequential. Most platforms don't surface this signal at all, which means their data quality silently degrades over time without anyone noticing.
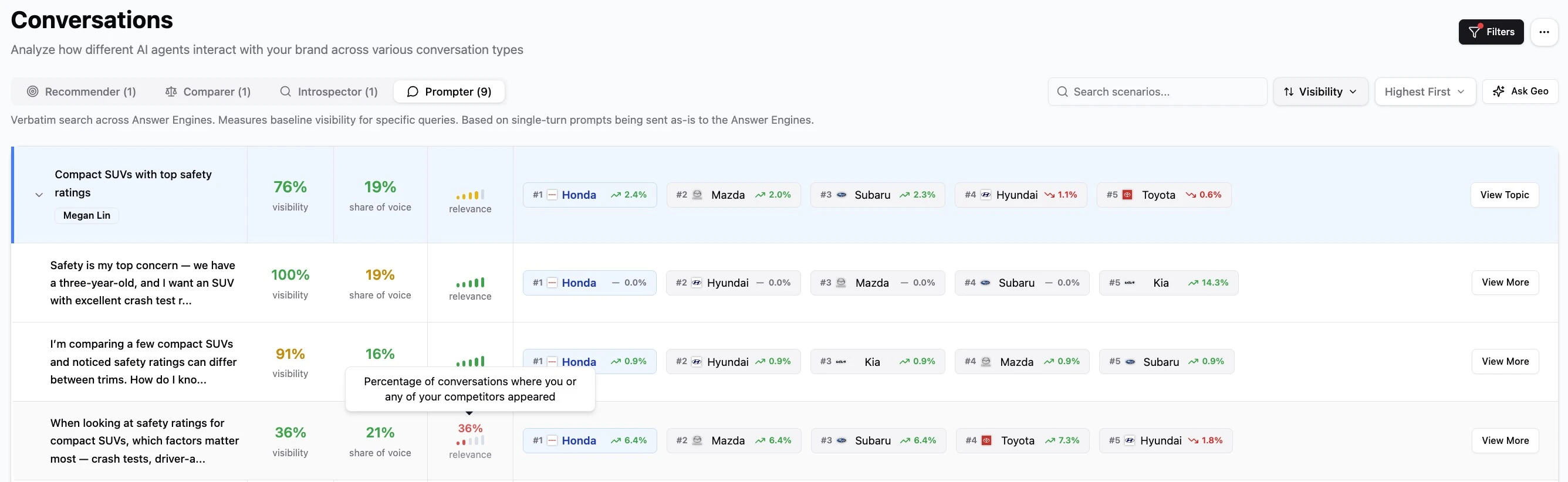
The Accuracy Dimensions That Are Now Table Stakes
These are now broadly covered by credible platforms. They're necessary, but they don't differentiate. Genezio covers them, but they're not where the buying decision should be made.
Coverage breadth. Multi-engine monitoring, multi-region testing, and multi-language support are now standard. Most platforms cover ChatGPT, Google AI Overviews, Perplexity, Claude, and Gemini with consistent methodology and support regional and language variants. Confirm with any vendor, but don't expect differentiation here.
Source accuracy. Tracing AI's answer back to specific cited URLs and domains. Most serious platforms extract citation sources at some level. Genezio provides URL- and domain-level citation extraction, citation footprint mapping, and competitive source comparison. Useful, not unique.
Temporal accuracy. Data refresh cadence. Most platforms offer some form of weekly or daily refresh. Genezio supports configurable cadences: weekly for priority prompts, monthly for full sets, quarterly for strategy refreshes. Standard for the category.
Governance accuracy. Enterprise procurement readiness. Genezio provides multi-brand management, role-based access, and the operational controls that survive enterprise security review. Important if you're an enterprise buyer, but increasingly available across credible vendors.
If a platform tells you these are their differentiators, they're underselling what matters and overselling what doesn't.
Use Cases: Where Accurate Data Matters Most
Executive reporting on the AI channel. Marketing leaders increasingly report on AI search alongside paid, organic, and direct. For this reporting to survive executive scrutiny, the underlying data needs to be defensible: consistent definitions, transparent methodology, statistical confidence framing, and a governance layer that lets you defend the numbers if challenged.
Competitive strategy in oligopoly markets. In concentrated categories like cloud infrastructure, enterprise software, financial services, and large-scale consumer brands, visibility metrics flatten near the top while the competitive dynamic remains active at the recommendation layer, often shifting by persona and context. Topic-level and persona-level competitor benchmarking surfaces where the position is actually moving.
Content and PR strategy prioritization. Marketing teams have limited bandwidth. The question isn't "what should we improve?" It's "what should we improve first, and what's the expected impact?" Persona-level and multi-turn intelligence make this decision based on data rather than intuition.
Multi-brand and multi-region programs. Enterprise organizations running multiple brands or operating across regions need governance and methodology that scales. Genezio supports separated reporting per brand with rollup to portfolio views, and region-specific monitoring with consistent methodology that allows cross-region comparison.
How to Evaluate Any AI Search Data Platform (Including Genezio)
These are the questions worth asking. Apply them to Genezio and to every alternative on your shortlist.
The Differentiating Questions
Measurement: Does the platform distinguish "mentioned" from "recommended" as separate metrics, or aggregate them? What are the specific scoring rules, and can you audit how individual prompts were scored?
Multi-turn: Does the platform track how brand presence changes across multi-turn conversation paths, or only at the initial query?
Persona segmentation: Can you configure prompt variants by persona? Is the reporting segmented at that level, or only aggregated?
Statistical confidence: Does the platform report confidence intervals alongside point estimates? This is one of the most differentiating questions in the category. Most platforms don't expose this at all.
Prompt relevance: Does the platform tell you when a prompt isn't returning any brand matches, yours or your competitors? Does it help you distinguish between "competitor set is incomplete" and "prompt isn't relevant to your category"?
The Table-Stakes Questions
Confirm these but don't let them drive the decision.
Coverage: Which AI engines, regions, and languages does the platform support?
Source extraction: Citation tracking at the URL and domain level?
Temporal: Refresh cadence, ad-hoc runs?
Governance: Role-based access, multi-brand separation, procurement-readiness?
If you ask the differentiating questions of any platform, you'll quickly separate platforms built for serious decision-making from platforms built for surface-level monitoring. Genezio is built for the former.
Getting Started With Genezio
Sign up. Configure your brand profile, core prompts, personas, and competitor set. The signup process establishes your baseline monitoring within hours. Visit app.genezio.ai/sign-up.
Run your baseline. Within 24 to 48 hours, you'll have visibility into your current recommendation rate, mention rate, competitive position by persona, citation sources, multi-turn outcomes, and any low-relevance prompts that need triage.
Ready to stop optimizing against noise? If you are evaluating GEO platforms and need decision-grade intelligence to drive your enterprise strategy, we can help. Book a strategy call with our team today to see how Genezio's accurate data can secure your brand's AI search visibility.
FAQ
Why does data accuracy matter more for AI search optimization than for traditional SEO?
In SEO, data sources are relatively standardized. Search Console, your analytics platform, established rank trackers, all measure roughly the same things using methodologies the industry converged on over two decades. AI search is different. Methodology is still evolving and varies dramatically between platforms. The platform you choose effectively defines what reality looks like for your AI search program.
What's the difference between "AI visibility" and "AI recommendations" in Genezio's methodology?
Visibility is whether your brand appears in an AI response. Recommendation is whether AI explicitly suggests your brand as a top option, describing it substantively rather than relegating it to a passing mention. The two are tracked separately because the gap between them is the most actionable diagnostic.
Why is multi-turn measurement important?
Real buyers don't ask AI a single question and stop. They ask, see options, then refine. Each refinement narrows the recommended set. A brand that appears in the initial top-5 but gets dropped at the first refinement has a problem that single-turn measurement won't reveal.
Why does persona segmentation matter?
The same product is perceived differently by different buyer types. AI may recommend you to developers and a competitor to procurement leads within the same company evaluating the same purchase. Aggregate recommendation rates hide this. Persona-segmented data tells you not just whether you're recommended, but to whom.
Why do confidence intervals matter?
AI search metrics are built on samples. Without confidence intervals, you can't tell whether a change reflects real movement or random variation in a small sample. Genezio attaches statistical confidence to every metric. The practical impact: decisions get made on signal rather than noise, and executive reporting can survive challenge.
What is prompt relevance scoring?
A monitoring program is only as accurate as the prompts you're running and the competitors you're tracking. Both can drift out of alignment with your market. When a prompt returns no brand matches, yours or your competitors, that's a signal. Either your competitor set is incomplete (AI is recommending brands you haven't classified) or the prompt isn't relevant. Genezio surfaces these cases and shows you what AI actually returned, letting you triage in real time.
Is Genezio appropriate for enterprise procurement requirements?
Yes. Genezio is built with enterprise procurement in mind: documented data handling, role-based access, multi-brand governance, and audit capabilities support standard vendor review processes.
How is Genezio different from SEO platforms that have added AI features?
SEO suites like Semrush and Ahrefs have added AI modules to their existing suites. Genezio is purpose-built for AI search optimization rather than as a feature layer on a different foundation. The differences show up where it matters: recommendation tracking as a first-class metric, multi-turn handling, persona segmentation, and statistical confidence.
Accurate data is the foundation of every AI search optimization decision worth making. The dimensions that differentiate, where the buying decision should be made, are the measurement distinction between mentioned and recommended, multi-turn conversation tracking, persona segmentation, statistical confidence, and prompt relevance. Genezio is built to deliver decision-grade accuracy across all five. The AI channel is too important to optimize against noise.

Read more about GEO, AI Search & Testing
Briefs, not articles: why we hand teams the blueprint, not the building
Any LLM can draft 1,500 words in seconds. But which words actually move the needle in AI search? Discover why data-backed content briefs are the secret to winning GEO.
Building the Future of Conversational Optimization: 2026 Outlook
Discover Genezio’s 2025 evolution into a Conversational Optimization Platform and explore the 2026 roadmap, featuring AI intent grouping, competitive intelligence, and self-serve tools.
5 Best AI Agents in 2025 (and How to Keep Them Reliable)
In this article, we'll take a look at the 5 best AI agents for 2025 and discuss why testing them is necessary to protect customer trust and satisfaction.