Agent Evaluation: A Framework for Businesses
In this article, we break down the main takeaways from the whitepaper and discuss how Genezio puts together the tools and support needed to carry out agent evaluations in real-world business scenarios.
Business owners need to evaluate agents more than ever before, considering AI-powered customer service keeps getting more complicated and accepted. Companies across industries are integrating AI agents to handle everything from simple FAQs to nuanced customer complaints. But how can a company be certain that these agents aren't hurting the customer experience or, worse, the company's reputation, but rather improving it?
Before getting to that answer, business owners and customer care executives need to understand the concept of agent evaluations.
When it comes to AI agents for customer support, it has become clear that it's easy to build a proof of concept, but incredibly difficult to guarantee high-quality, production-ready results in gen AI. And that is the central topic of a recent Kaggle whitepaper titled "Agent Companion: A Framework for Evaluating LLM Agents." It provides a compelling and structured approach to solving this very problem. It proposes a repeatable, modular framework to assess the behavior and effectiveness of AI agents in customer service settings.
In this article, we break down the main takeaways from the whitepaper and discuss how Genezio puts together the tools and support needed to carry out agent evaluations in real-world business scenarios.
What are AI agents?
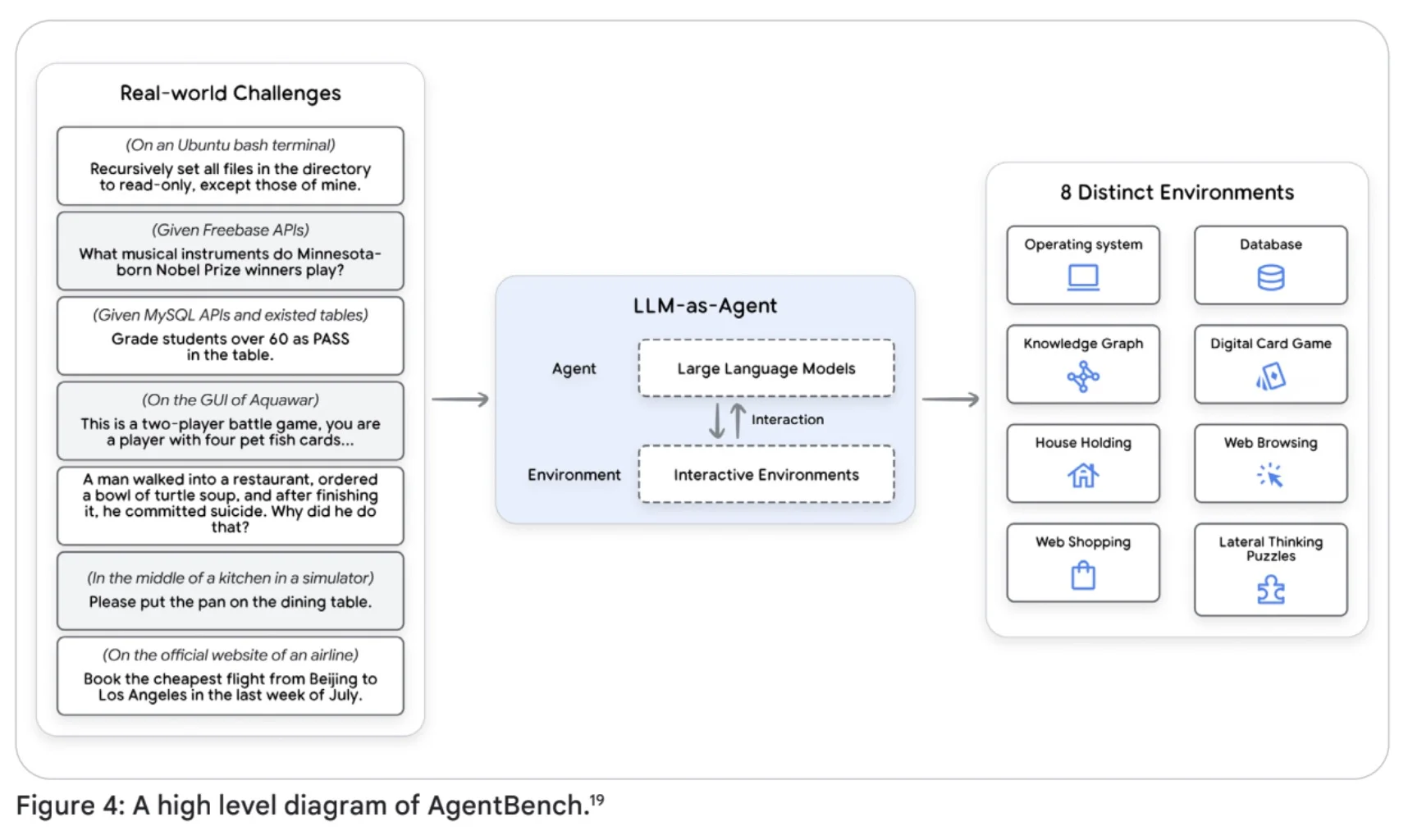
As outlined in the Kaggle whitepaper, an agent is not just a chatbot. It's an application engineered to achieve specific objectives by perceiving its environment and strategically acting upon it using the tools at its disposal.
What sets agents apart from basic language models is their ability to reason, plan, and access external systems. They're designed to make decisions autonomously and adapt to changing contexts without constant human input. In essence, they can act with purpose---even without being told exactly what to do every step of the way.
That autonomy is powerful, but also dangerous. Without proper agent evaluation, how do you verify that your agent is choosing the right course of action? This is the core question the Kaggle framework addresses.
What is an agent evaluation and why it matters
Evals in AI are structured tests designed to evaluate how effectively an AI system handles a particular task. For customer service bots, this involves assessing how well it understands customer questions, the accuracy of its responses, and how well its tone and behavior reflect the brand's values.
The cost of deploying a poor-performing AI agent is enormous. From mishandled queries and frustrated customers to potential brand damage and revenue loss, bad AI can quickly spiral into real-world consequences. That's why businesses need systematic agent evaluations, before and after deployment.
The Agent Companion whitepaper emphasizes that AI agents are only as good as the process behind them. Businesses must evaluate agents not just for technical performance, but for human-centric quality: helpfulness, tone, empathy, and adaptability. And crucially, these evaluations shouldn't be left solely to engineers or data scientists --- customer care professionals, brand strategists, and legal teams must all have input.
To understand its importance, think about the amount of big name companies that had front page AI related scandals in the past year, like Air Canada. In July 2022, the airline's bot told a customer he could apply a discount retroactively after buying a ticket for his grandmother's funeral. However, when the man demanded the reimbursement, the airline refused and claimed the chatbot was a "separate legal entity" responsible for its own actions. A judge ruled against Air Canada, and stated the airline is ultimately responsible for all information provided by its chatbot. As a result, the company had to refund the ticket and pay damages.
Key takeaways from the Agent Companion Whitepaper
The whitepaper is an extensive resource for developers looking into agent evaluations. However, it highlights a few key takeaways for both businesses and customer care executives aiming to deploy AI agents in customer care.
First, the concept of AgentOps is foundational. Just as DevOps transformed the reliability of software delivery, AgentOps is about applying a similar discipline to the world of generative AI agents. It emphasizes continuous evaluation, orchestration, memory management, and thoughtful task decomposition. You need systems that verify it works reliably and contextually, every time.
| Evaluation Method 👁️🗨️ | Strengths 👍 | Weaknesses ⛔ |
|---|---|---|
| Human Evaluation | Captures nuanced behavior, considers human factors | Subjective, time-consuming, expensive, difficult to scale |
| LLM-as-a-Judge | Scalable, efficient, consistent | May overlook intermediate steps, limited by LLM capabilities |
| Automated Metrics | Objective, scalable, efficient | May not capture full capabilities, susceptible to gaming |
Source: Kaggle whitepaper
Next, metrics are important, but they need to be based on real business results. Whether it's task success rates, user satisfaction, or conversion, AI agents should be tied to KPIs that truly reflect user impact. Automated metrics like trajectory evaluation and response scoring must complement---not replace---human-in-the-loop evaluation. Human judgment is still the gold standard for assessing qualities like empathy, tone, and usefulness. Importantly, this evaluation should be easy to conduct by customer experience teams, not just engineers.
Third, the whitepaper proposes automated and human evaluations working together. Agent traces --- the path an agent takes to reach an answer --- need to be auditable and measurable. The paper also highlights the potential of multi-agent systems for complex tasks. Businesses can achieve better performance and redundancy by combining agents in collaborative or hierarchical ways. Similarly, agentic RAG, where agents actively refine and optimize retrieval queries, opens the door to more accurate and context-aware answers. But both innovations underscore the same truth: without robust evaluation, complexity becomes chaos.
Finally, the whitepaper emphasizes the importance of platform choices. Businesses should consider platforms that abstract away technical complexity while allowing them to focus on what matters: their users and their data.
From framework to execution: Genezio lets technical and non-technical teams test AI agents
The Agent Companion framework is a valuable roadmap, but turning it into a working system takes more than good intentions. That's where Genezio's agent evaluation service comes in. Genezio offers a platform built to bring agent evaluation into real-world customer service environments.
And it does so in a way that's accessible for non-technical teams, so that everyone, from support managers to legal reviewers, can play a role in evaluating AI agents.
Genezio is a platform designed to run real-world simulations for generative AI agents. It enables teams to test their AI agents before launch and continue monitoring them in production through automated testing in complex scenarios. These evaluations cover functionality, performance, security, and compliance to guarantee that agents stay aligned with business goals and evolving industry standards.
Businesses can simulate multiple agents in different regions with Genezio. They can also get detailed reports, either once or on a regular basis, and learn about potential weaknesses and performance gaps.
Running evaluations with Genezio is simple: define the agents, launch simulations, and receive a detailed report within 24 hours. It's the fastest and most affordable way to implement the Agent Companion's agent evaluation framework into your own gen AI.
Run your agent evaluations with Genezio
The Agent Companion whitepaper gives businesses a uniform blueprint for assessing AI agents. But blueprints alone don't build your home. To truly take advantage of agent evaluation, businesses need tools that bring theory to life.
Genezio is that tool. It helps you track your bots' factuality, hallucinations, tracks risky patterns and even examines prompt injection attacks. You can choose to get a one-time report, or set up continuous monitoring and receive periodic reports.
Begin running your agent evaluations with Genezio for free and get your first report in 24hrs.
